
Thoughts For The Week - 2025.11.23
AI Development: Orchestration, Validation Loop, Spec Driven
This week’s post is a deep dive into Fran Soto’s excellent post…

Takeaway Nugget 1: “Productive Engineers do not hope AI gets it right, they steer it”
Takeaway Nugget 2: Explicit validation loops build natural checkpoints that help force consistency.
Takeaway Nugget 3: Use specs at the start but then focus on the data flows and structures.
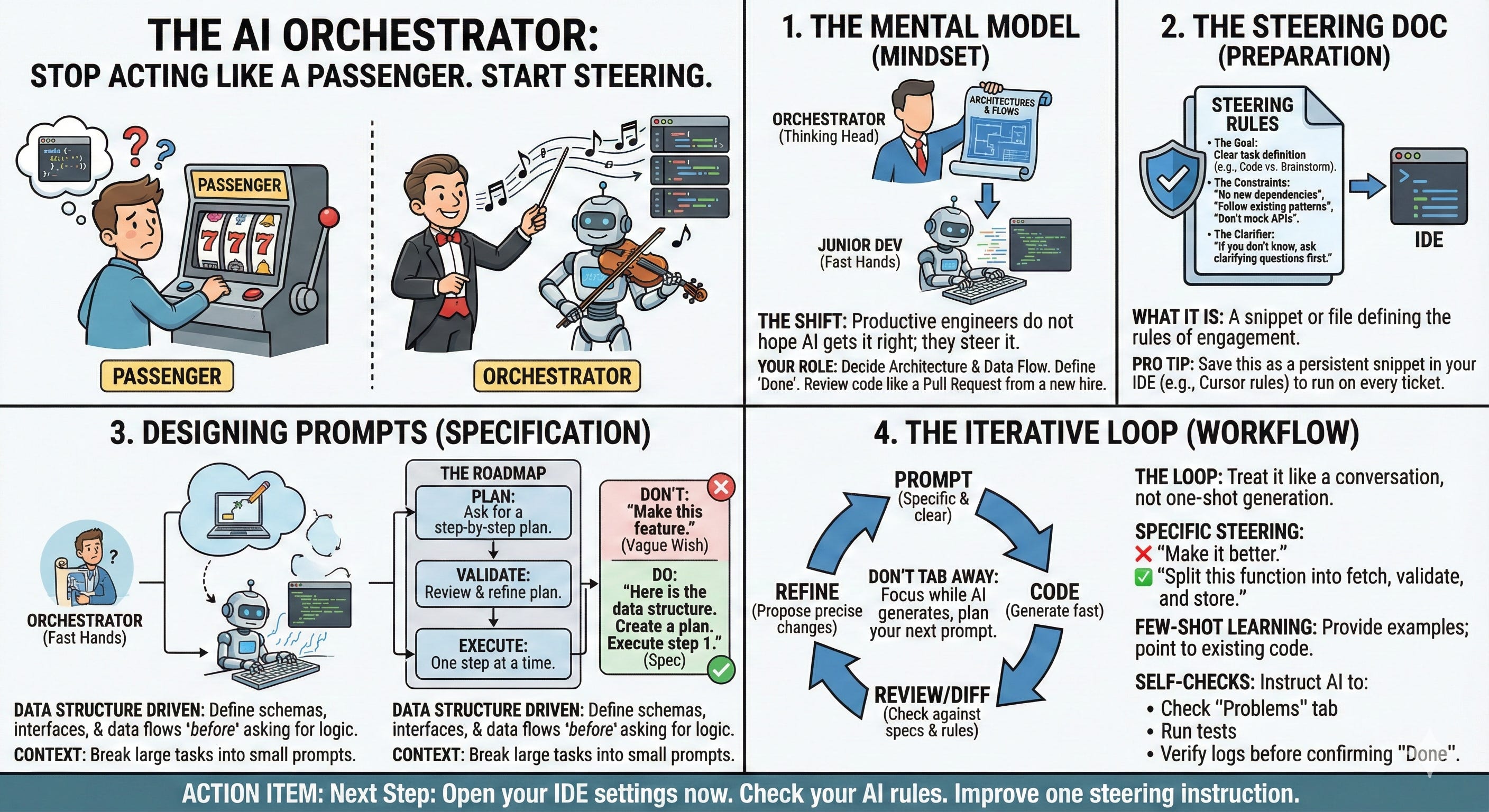
1. Be the orchestrator. Think a head.
Reviewing AI output is another place where the orchestrator mindset matters. I noticed a lazy habit in myself. Once the AI code worked, I did not want to go through it in detail. The tests passed, so my brain wanted to move on. That is a trap. AI is not yet at the level where you can skip review. You need to treat its output like a pull request from a new hire. First check the structure, then the happy path, then edge cases...
Takeaway Nugget 1: “Productive Engineers do not hope AI gets it right, they steer it”
2. Create Steering Rules - A Validation Loop
Your prompts should not be one offs. Creating an explicit validation loop is a good way to help force this process. This keeps quality up, ensures that errors don’t get overlooked and forces natural check points.
Cole Medin has some great templates on GitHub
Validation Loop
Phase 1: Linting
Run the actual linter commands found in the project (e.g.,
npm run lint,ruff check, etc.)Phase 2: Type Checking
Run the actual type checker commands found (e.g.,
tsc --noEmit,mypy ., etc.)Phase 3: Style Checking
Run the actual formatter check commands found (e.g.,
prettier --check,black --check, etc.)Phase 4: Unit Testing
Run the actual test commands found (e.g.,
npm test,pytest, etc.)Phase 5: End-to-End Testing (BE CREATIVE AND COMPREHENSIVE)
Test COMPLETE user workflows from documentation, not just internal APIs.
Takeaway Nugget 2: Explicit validation loops build natural checkpoints that help force consistency.
3. Spec Driven Approach
There is also a downside with heavy spec systems. My team tried “spec driven development” in the style of AWS Kiro. The idea is nice, but in practice it was super verbose and painful to maintain. I saw pull requests with 22 times more markdown line changes than code changes. AI was not good enough to keep a perfect mirror between code and specs. My takeaway is to keep minimal specs focused on data models and interfaces. Once the code exists, I reference the code itself and delete the markdown.
I’ve been trying kiro this weekend. I see the spec driven approach as a massive step forward from adhoc "vibe coding style prompts. For small green field projects especially at the start I believe the specs add a lot of value. But I fully take Fran’s point from above. Once you have the code you have a lot of duplication between specs and code and I can see that the older the projects get the more divergence there will be.
Takeaway Nugget 3: Use specs at the start but then focus on the data flows and structures.
Have a great week.